- Home
- Constraints
- Fit Results
- Historical Plots
- Papers and Conferences
- CKM Formalism
- Statistical Method
- Contacts
- Feedback
Description of the Bayesian method
The method is explained in detail in M. Ciuchini et al., JHEP 0107 (2001) 013, hep-ph/0012308. Given N parametersand M constraints
, whose actual value depends on
and on CKM parameters
, what is the best determination of
where is the p.d.f. for the constraints or parameters and
is the a-priori probability for
Several remarks are in order: How do we treat inputs?
- The present knowledge of each quantity is expressed with a p.d.f. or, if you prefer, with a Likelihood function (in the Bayesian approach is always possible to define a p.d.f. as
).
- The method does not make any distinction (formally) between theoretical and experimental parameters or between Gaussian and non-Gaussian distributions. It can easily digest any kind of p.d.f./Likelihood (unlike other methods).
- The Bayesian concept of updating the knowledge is naturally applied. Starting from no information on the actual value of
and
, one can update (and improve) it using the available experimental and theoretical information.
The final p.d.f. of the parameter is computed as a convolution between all the uncertainties. Consider the following example of a p.d.f. for a theoretical parameter:
- When available, we use the experimental likelihoods.
- If a parameter has an uncertainty given as "allowed range" we assume this parameter to be uniformly distributed in the range. This could apply in principle both to theoretical estimates or to experimental systematics.
The interpretation of the result of a Bayesian fit is well defined probabilistically, since the output of the fit is given in terms of p.d.f.'s.
- The most relevant (but unavoidable) assumption is on the size of the range (flat part) of the theoretical uncertainty, not in the shape of the p.d.f.
- The central value is preferred (as expected).
- The allowed regions are well defined in term of probability. Allowed regions at 95% mean that you expect the "true" value in this range with a 95% probability (and not "at least 95%" as, by definition, in the frequentist approaches).
- Any p.d.f. can be extracted by changing the integration variables → indirect determination of any interesting quantity (theoretical parameter, unmeasured quantities)




Other methods
Other statistical approaches are based on a frequentist understanding of systematic theoretical uncertainties, which cannot be treated as statistically distributed quantities. In this framework two main approaches can be distinguished : the Rfit method and the Scanning method. In both methods, the "theoretically allowed" values for some theoretical parameters are "scanned", i.e. no statistical weight is assigned to these parameters as long as their values are inside a "theoretically allowed" range.
At present three groups are producing results in this framework:The Rfit and the Scan methods are also described in Chapter V of the Yellow Report (CERN-EP/2003-002, hep-ph/0304132).
- Rfit Group (hep-ph/0104062), see also the web page).
- Frequentist-K.Schubert (proceedings at CKM workshop).
- Scan Group (hep-ph/0308262).
Comparison between Rfit and Bayesian methods
The comparison between Rfit and Bayesian methods has been done during the first CKM Workshop held at CERN on 13-16 February 2002. The results are reported in Chapter V of the Yellow Report (CERN-EP/2003-002) ( hep-ph/0304132). We summarize here the main results.
The aim of this comparison was to evaluate the difference in the output quantities as obtained from the two statistical methods and not to judge their validity (statistical foundation). At the Workshop it was concluded that the output results differ mainly because of the different treatment of the input quantities.
Treatment of the input quantities
The treatment of the inputs differ between the two methods. The uncertainty on a quantity is usually split in two parts: a statistical part which can be described by a Gaussian p.d.f., (this part may contain many sources of uncertainties which have been already combined into a single p.d.f.) and another part which is usually of theoretical origin and is often related to uncertainties due to theoretical parameters. In the following we will denote it as theoretical systematics. It is often described using an uniform p.d.f. The resultant p.d.f. is obtained from the convolution of the two p.d.f.'s, which is, obviously, not necessarily a Gaussian p.d.f.
In the frequentist analysis, no statistical meaning is attributed to the uncertainties related to theoretical systematics. The likelihood function which describes this quantity is obtained as a product between this uncertainty and the statistical one (which corresponds to a linear sum of the errors).
In conclusion even if the inputs used are the same in the two approaches (in term of Gaussian and uniform uncertainties), they correspond to different input likelihoods. An example, using the quantity BK, is given below.Table of inputs used for this comparison
Constraints, Parameters Value Gaussian Error Flat Error Comments 0.762 0.064 - - 0.2210 0.0020 - - 42.1 2.1 - Average of exclusive 40.4 0.7 0.8 Average of inclusive 32.5 2.9 5.5 For the moment → only CLEO 40.9 4.6 3.6 For the moment → LEP + CLEO endpoint 0.494 0.007 - WA (CDF/CLEO/LEP/BaBar/Belle) >14.5 @ 95% C.L. - - Sensitivity at 19.3 (CDF/LEP/SLD)
The Likelihood Ratio is used.167 5 - (CDF/D0) 230 30 15 Lattice QCD 1.18 0.03 0.04 Lattice QCD Comparison of output quantities
For the comparison of the results of the fit we useand
. Those quantities are compared at the 95%, 99% and 99.9% C.L.. It has to be stressed that in the frequentist approach those confidence levels correspond to >95%, >99% and >99.9%.
Allowed regions for ,
,
,
, and
The origin of the residual difference between the two methods has been further tested performing the following tests: both methods use the distributions as obtained from Rfit or from the Bayesian method to account for the information on input quantities. The results of the comparison using the input distributions as obtained from Rfit are shown in the Figures below and the results are summarized in the Table below. In some cases (99.9% and 99% C.L.) the ranges selected by the Bayesian approach are wider. The comparison using the input distributions, as obtained from the Bayesian method, give a maximal difference of 5%.
Parameter 95% C.L. 99% C.L. 99.9% C.L. 1.43 1.34 1.12 1.18 1.12 1.05 1.17 1.18 1.16 1.46 1.31 1.09 These two tests show that, if same input likelihoods are used, the results on the output quantities are very similar. The main origin of the residual difference on the output quantities, between the Bayesian and the Rfit method comes from the likelihood associated to the input quantities.
Parameter 95% C.L. 99% C.L. 99.9% C.L. 1.20 1.13 0.96 1.03 0.99 0.94 1.07 1.08 1.07 1.24 1.12 0.95
We report here the conclusion as written in Chapter V of the Yellow Report (CERN-EP/2003-002) (hep-ph/0304132).
"The Bayesian and the Rfit methods are compared in an agreed framework in terms of input and output quantities. For the input quantities the total error has been split in two errors. The splitting and the p.d.f distribution associated to any of the errors is not really important in the Bayesian approach. It becomes central in the Rfit approach where the systematic errors are treated as "non statistical" errors. The result is that, even if the same central values and errors are used in the two methods, the likelihood associated to the input parameters, which are entering in the fitting procedure, can be different. The output resultsdiffer by 15%-45%, 10%-35% and 5-15% if the 95%, 99% and 99.9% confidence regions are compared, respectively, with ranges from the frequentist method being wider. If the same likelihoods are used the output results are very similar.

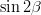

![\left | V_{cb} \right |~[10^{-3}]](/foswiki/pub/UTfit/Method/_MathModePlugin_fc4661c2241d0f10c4a25aff9ae90e4e.png)
![\left | V_{ub} \right |~[10^{-4}] \mathrm{(excl.)}](/foswiki/pub/UTfit/Method/_MathModePlugin_b2cc05b80c5a18e3f97b1d3243c75007.png)
![\left | V_{ub} \right |~[10^{-4}] \mathrm{(incl.)}](/foswiki/pub/UTfit/Method/_MathModePlugin_38236d194dff1b2117145d3b723f39bc.png)
![\Delta m_d~[ps^{-1}]](/foswiki/pub/UTfit/Method/_MathModePlugin_d8d6be4b6a774788c18ee6d0c92506fc.png)
![\Delta m_s~[ps^{-1}]](/foswiki/pub/UTfit/Method/_MathModePlugin_c981187e0dfde242fddf843217eed79c.png)
![m_t~[GeV/c^2]](/foswiki/pub/UTfit/Method/_MathModePlugin_505762405777afe7e25bf6489fff3318.png)
![f_{B_d}\sqrt{B_{B_d}}~[MeV]](/foswiki/pub/UTfit/Method/_MathModePlugin_d95b9ee30816b5764305309b5e8e6946.png)


Powered by
 Ideas, requests, problems regarding this web site? Send feedback
Ideas, requests, problems regarding this web site? Send feedback